Recently I spend some time on pySpark to see if it could help our team to resolve some of the problems we are facing on apache airflow. airflow is a great tool for scheduling, triggering and monitoring etl jobs, but itself is not a data processing tool, we are trying to use apache airflow to act as both scheudling tool and data processing tool, here comes a problem, we have only one airflow cluster anytime airflow get redeployed, some running jobs got a chance to get interrupted. there are some ways to overcome this issue, but still running differnt jobs on the same cluster is not a good idea. it's ideal to have each data processing job running on it's dedicated cluster and isolated from each other. Spark support to deploy to kubernetes out of box from v2.3, and we could create dedicated spark cluster for any single spark job. as our team prefer python as the first development language , so pySpark looks like a perfect tool to look into.

pySpark image
spark team does not provide pre-build docker image for spark, but it provide a docker-image-tool.sh to build an push spark images to docker registory, I've built an image email2liyang/spark-py and publish it to github for public use, we could also use this image as a base image and custome spark-py image to meet team's own need. for example, install additional software packages or install some python dependencies, I will take about this later.
pySpark project setup
I use pipenv to manage my python project dependencies,you could check this article for how to use pipenv for details. there could be 2 main folders in the project
- vip_udfs: hold the business logic for all the jobs, different logic could be separated in different python package, it mostly expose as user defined function(udf), the udf could be tested as standard pthon function as well
- vip_jobs: hold the main pySpark jobs , it in charge of create the spark job and set the dependency path etc. it will call udf defined in package vip_plugins
python dependency management
the python dependendcies is the python code which is expected to be in each worker's runtime python path, so that the pySpark job could invoke the funcitons provided from the dependencies. there are 3 kinds of dependencies
- the 3rd party python dependencies
we could use pipenv to install the 3rd party python dependencies into local env and expose them viapipenv lock -r > requirements.txt, when we build custom docker image based on spark-py, we could install these dependencies. - the UDF defined in folder
vip_udfs
these are the user defined functions which support the main pySpark jobs,these python module could be packaged as a zip file and send to a shared volume in the spark cluster, in my case I've provision an AWS EFS and mout it as shared volume across all the pySpark worker pods, let's assumevip_udfsis packaged as vip_udfs.zip and copied to path/var/efs/pyspark/job-station/vip_job1/vip_udfs.zip
to make the spark worker could access this type of python dependencies, in our pySpark job, we need to write like below
spark_session = SparkSession \
.builder \
.appName("vip_job1") \
.getOrCreate()
spark_session.sparkContext.addPyFile('/var/efs/pyspark/job-station/vip_job1/vip_udfs.zip')
- the 3rd party jars
spark is written in Scala and running on JVM, so the core spark runtime is running in JVM , we could also utilise some 3rd party java lib to help us on some tasks in the flow. e.g: load data from mysql through mysql jdbc. to do this , we could copymysql_mysql-connector-java-5.1.44.jarinto a shared location, e.g:/var/efs/pyspark/jars/mysql_mysql-connector-java-5.1.44.jarand in spark-submit, we could delcaer the additional jar via--jarsoptions.
sumbit pyspark job into kubernetes
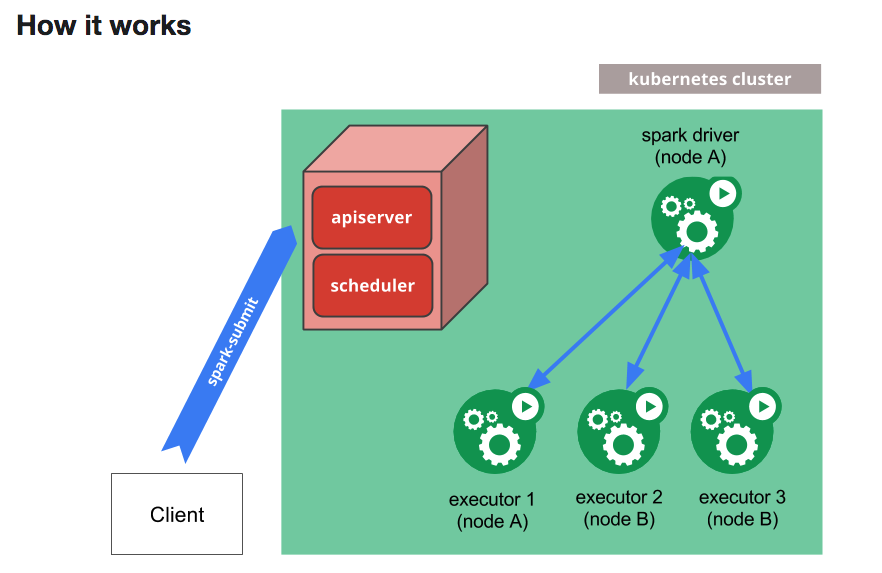
below is the pySpark architecture on kubernetes, we could use spark-submit utility to submit the pySpark job into kubernetes cluster, it will create a driver pod first, and the driver pod will also communicate with api server to create executor pod as defiend, the driver pod also in charge of all the job pod's life cycle, we only need to manage the driver pod.
below is a sample command to submit a pySpark job into kubernetes cluster with explanation on each option
spark-submit \
# the kubernetes api point, we need to config kubectl to be able to access this
--master k8s://https://xxxxx.aa.us-east-1.eks.amazonaws.com:443 \
# declare we use cluster mode
--deploy-mode cluster \
# the 3rd party jar which could be access from all the spark runtime
--jars /var/nfs/pyspark/jars/mysql_mysql-connector-java-5.1.44.jar \
# the udf files which could be access from the driver node
--py-files local:///var/efs/pyspark/job-station/vip_job1/vip_udfs.zip \
# spark could run on under dedicated service account
# an rbac config is needed for this service account to access kubernetes api
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-sc \
# the spark could run all the spark job in it's own namespace
--conf spark.kubernetes.namespace=spark \
# when we build custom docker image
# it could be stored in a private docker registery e.g:gcr
# this secret name is used to pull the image from private docker registry
--conf spark.kubernetes.container.image.pullSecrets=vip-mind-docker-registry \
# the custom pyspark image to pull from docker registry
--conf spark.kubernetes.container.image=us.gcr.io/vip-mind/my-pyspark:latest \
# specify how offten you want to pull the new image
--conf spark.kubernetes.container.image.pullPolicy=Always \
# the job name
--name vip_job1 \
# how many executors you want the driver to create
# in this case the driver pod will create 10 executor pods to process the data
--conf spark.executor.instances=10 \
# currently spark support both python 2 and python3
# but spark will drop python 2 in a short time
# so it's recommended to use python 3
--conf spark.kubernetes.pyspark.pythonVersion=3 \
# we could mount additional pv into the driver pod, e.g: the efs
# so that driver could access the shared efs volume
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.efs-pvc.mount.path=/var/efs \
# do we mount the volume as readOnly?
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.efs-pvc.mount.readOnly=false \
# which pvc we should claim from for the efs
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.efs-pvc.options.claimName=efs \
# we could mount additional pv into the driver pod, e.g: the efs
# so that driver could access the shared efs volume
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.efs-pvc.mount.path=/var/efs \
# do we mount the volume as readOnly?
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.efs-pvc.mount.readOnly=false \
# which pvc we should claim from for the efs
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.efs-pvc.options.claimName=efs \
# we could also assign the spark to run on specific ec2 nodes
--conf spark.kubernetes.node.selector.beta.kubernetes.io/instance-type=m5.large \
# we could also set the how much cpu or memory when launch the executor pod
--conf spark.kubernetes.executor.request.cores=300m \
# the py spark main job file
local:///var/efs/pyspark/job-station/vip_job1/main.py